Structural Topic Modeling with R — Part I

Topic models allow us to summarize unstructured text, find clusters (hidden topics) where each observation or document (in our case, news article) is assigned a (Bayesian) probability of belonging to a specific topic.
The most common form of topic modeling is LDA (Latent Dirichlet Allocation). Other techniques exist, such as Dynamic Topic Models, Correlated Topic Models, Hierarchical Topic Models.
Structural topic modeling (STM) has been increasing in popularity over recent years. STM is essentially LDA that employs metadata to improve word assignment to topics within a corpus (collection of news articles).
So we can easily say, STM = LDA + metadata.
We will be using the Daily Financial News dataset published on Kaggle. The dataset includes approximately 2 million articles for 6000 stocks from 2009–2020.
There is an R package called stm, which provides almost everything we need for our first Structural Topic Model.
Let's load the required libraries (these will be used in Part II of this article as well):
Load original dataset and check for NAs:

Let's randomly sample 1,000 rows out of the loaded dataset (feel free to reduce the sample size if your laptop can't handle it).

We will apply few preprocessing steps to our sample, including:
• Convert to lower case
• Remove Stop-Words
• Remove numbers
• Remove punctuation
• Words shorter than the minimum word length are discarded
• Stemming
• Replace all non-alphanumeric characters
• Create output
The processed object is a list of four objects: documents, vocab, meta, and docs removed. The document object is a list, one per document, of 2-row matrices; the first row indicates the index of a word found in the document, and the second row indicates the (nonzero) counts. If preprocessing causes any documents to be empty, they are removed, as are the corresponding rows of the meta-object.
Let's filter out terms that do not appear in more than ten documents (our threshold — you can change this as desired).
Also, we will level check for “publisher” and “stock” columns before proceeding with the structural topic model.


Let`s run our initial topic model [prevalence =~ publisher + date] at 15 topics (without finding optimal k), see how long it takes to run, and what the output looks like.


We can run a second preliminary topic model [prevalence =~ publisher + date] at 18 topics (without finding optimal k) but add 75 iterations, see how long it takes to run, and review its respective output.
Both STM models produce meaningful topics and keywords.
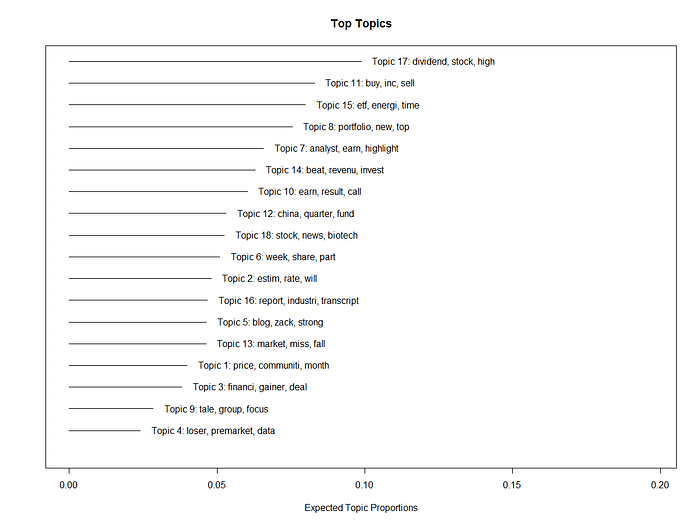
Next, we need to identify the number of optimal topics.
I will showcase three approaches in finding an optimal number of topics (k) that we can apply to the final version of our STM:
• Approach 1: use “searchK” function and look through 10 to 30 topics; no other parameters set
• Approach 2: use “searchK” function, search through 10, 20, 30, 40, 50, 60, 70 k tries, N= 500 and 75 iterations
• Approach 3: “Lee Mimno” via stm where k=0 and iterations = 75
Approach 1 takes approximately 23 minutes on i7 CPU. The guideline is usually where the held-out likelihood is highest, and the residuals are lowest. It looks like 17 optimal topics under this approach.

Approach 2 takes approximately 6 minutes. It looks like 20 optimal topics under this approach.


Approach 3 takes approximately 29 seconds. It looks like 27 optimal topics under this approach.

Based on the above, I have decided to run the final STM on 20 topics. The final STM runs in about 20 seconds.

In Part II of this article, I will evaluate the model and explore other aspects of structural topic modeling.
If you find this article of interest, please like and comment. Until next time!
Reference:
- The Structural Topic Model and Applied Social Science. https://scholar.princeton.edu/files/bstewart/files/stmnips2013.pdf
- stm package for R. https://www.structuraltopicmodel.com/
